
 for Responsible Care of Dementia and Frailty 2")
The complexity of machine learning and artificial intelligence-driven models in medical expert systems raises concerns about their interpretability. Physicians and patients may be hesitant to trust recommendations from a “black box” model without clear explanations of the decision-making process. Ensuring transparency and explainability is crucial for fostering trust and clinical acceptance. To address this challenge, the COMFORTage project is implementing a dedicated task (Task. 3.5) which, starting from state-of-the-art XAI models and approaches, will specify and implement a framework for scoring the explainability of the different models towards comparing alternative approaches, balancing performance vs. explainability trade-offs. These techniques will boost the transparency and interpretability of AI-based personalised recommendations, preventions, and interventions enabling health-care professionals and health public/private policymakers to develop trusted and interpretable healthcare policies. At the same time, they will be of help for formal/informal caregivers to understand, interpret and evaluate the outcomes of AI-based decisions and recommendations.
Overview of Explainable AI (XAI) Techniques
As the field of XAI is evolving rapidly, many prediction explanation techniques have been developed. Model-agnostic methods derive prediction explanations independently of any knowledge of the underlying black-box model. They are categorised into local and global, depending on the number of predictions they aim to explain. Local methods focus on a single prediction at a time, while global methods generally use the training set to draw overall conclusions about the way in which the features influence the predictions of a model. Some state-of-the-art XAI techniques include:
- SHAP, which leverages game theory to assign important values to features by considering their contribution to a model’s prediction. This method ensures a consistent and comprehensive measure of feature importance.
- LIME, that builds local surrogate models around individual predictions, offering an interpretable approximation of any classifier’s behaviour within a specific neighbourhood of the data.
- DeepLift (Deep Learning Important FeaTures) which compares neuron activations to reference activations, attributing contributions to each feature based on the observed differences.
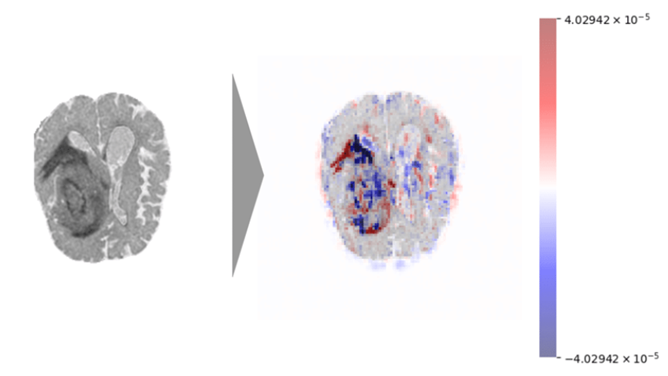
Challenges of Multimodal Biomarker Data in Dementia Modelling
Biomarker datasets are inherently complex, including multimodal inputs like imaging, genomics, proteomics, and clinical data. Combining these diverse data types while maintaining interpretability is difficult. For example, a dementia model might integrate MRI scans (spatial data), genetic risk factors (tabular data), and cognitive scores (time-series data). Explaining how these modalities interact to predict risk is non-trivial. To this end, SHAP is useful for explaining model predictions by attributing importance to individual features (e.g., APOE genotype’s contribution to dementia risk) and LIME can generate local explanations for individual predictions, highlighting specific biomarker contributions for a single patient.
In addition, clinicians need reasonable and actionable insights from XAI systems. Explanations must be intuitive and directly relevant to decision-making, such as identifying specific biomarkers for early interventions. For example, a clinician using an AI tool might want to understand why the model predicts an elevated risk of frailty and how modifying lifestyle factors could mitigate this risk. Relevant methods include scopes rules (anchors), that is, a rule-based XAI method that provides if-then explanations, offering clear decision rules clinicians can follow, as well as partial dependence plots (PDPs) to visualize the relationship between a biomarker (e.g., BMI) and predicted frailty risk.
Current Experiments with SHAP on the ALBION Dataset
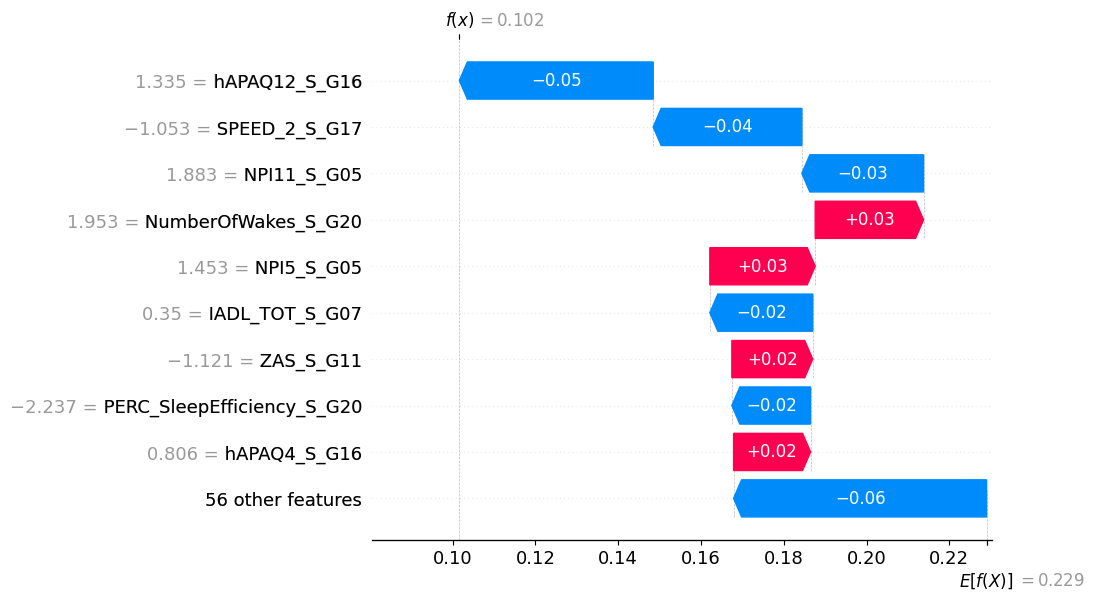
We have begun our experiments for the COMFORTage platform using SHAP as the main explainer and performing a smaller number of experiments with LIME. So far, SHAP has been tested on the ALBION dataset from Aiginiteio Hospital. A neural network was initially developed, and SHAP was subsequently used to enhance the interpretability of the results. The use of SHAP allowed us to identify the most significant factors influencing the model’s predictions (Figure 3). The initial results indicated that specific clinical features played a crucial role in the final prediction, confirming findings from previous studies while also highlighting new potential associations.
Our aim is to define a minimal subset of these XAI models that will be able to provide sufficient explanations to our end users, while achieving the best overall performance. We may consider adding pilot-specific techniques on a case-by-case basis. While this would increase the complexity of the technical undertaking, it certainly merits exploration, since the project includes a diverse set of pilots with different protocols and end goals. It must also be noted that a subset of clinical tasks will be tackled using inherently interpretable models (regression, decision trees), and thus the additional insights they provide into their decision process can also be made available to our end users.
References
Eder, M., Moser, E., Holzinger, A., Jean-Quartier, C., & Jeanquartier, F. (2022). Interpretable Machine Learning with Brain Image and Survival Data. BioMedInformatics, 2, 492–510. https://doi.org/10.3390/biomedinformatics2030031
Laguna, S., Heidenreich, J. N., Sun, J., Cetin, N., Al-Hazwani, I., Schlegel, U., Cheng, F., & El-Assady, M. (2023). ExpLIMEable: A Visual Analytics Approach for Exploring LIME. 2023 Workshop on Visual Analytics in Healthcare (VAHC), 27–33. https://doi.org/10.1109/VAHC60858.2023.00011
**Article written by University of Patras (UPAT), a key partner in the COMFORTage project.